gRPC 中的客户端重试
gRPC 提供了非常复杂的自动重试策略。其中按照重试时机可以分为简单 retry 和 hedging 两种。按照业务上划分可以分为透明重试和非透明重试。

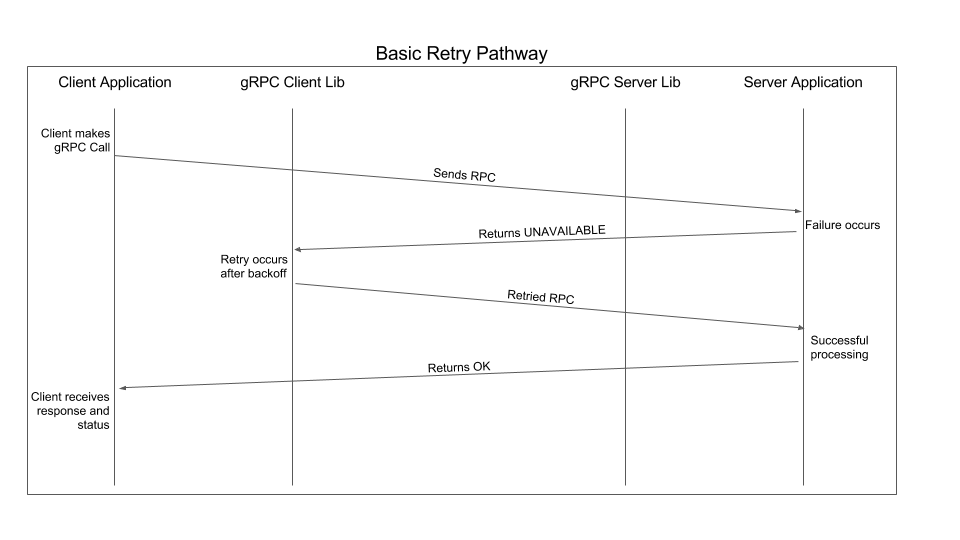
简单 retry
其中简单 retry 配置如下:
1 | "retryPolicy": { |
当 gRPC 收到不正常的 response 时,首先会通过以下几点来判断是否进行简单重试:
- 会通过 response 中对应的 status 来决定是否进行重试
- 请求本身是否超过 deadline
- 请求次数是否超过 maxAttemps,原始请求也被计算在 maxAttemps 中
重试间隔由 initialBackoff 和 maxBackoff 以及 backoffMultipiler 决定:
- 首次重试间隔为:random(0,initalBackoff)
- 第 n 次重试间隔为:min(initialBackoff * backoffMultiplier ^ (n-1), maxBackoff)
hedging policy 配置如下:
1 | "hedgingPolicy": { |
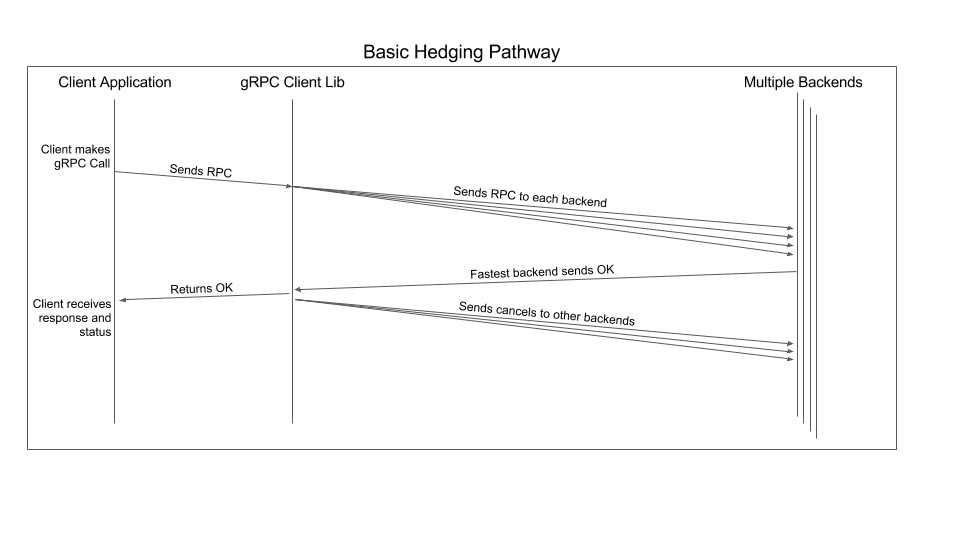
hedging
hedging 策略下当原始请求被发出后,当过了 hedingDelay 时间之后如果客户端还没有收到 response,就会发出 hedging request 请求,直到达到 maxAttemps 或者超过 deadline。
- 一旦客户端收到成功的 response ,则会立即取消掉其他的 request 。
- 如果收到 non-fatal 状态码,下一个 hedging 请求会立即发出,以缩短延时。
除了简单 retry 和 hedging 之外,重试也会受到下列配置的影响来避免服务端过载:
1 | "retryThrottling": { |
gRPC 内部会维护一个 token_count 来,token_count 初始值为 maxTokens ,并在 0 和 maxTokens 之间变动:
- 只有当 token_count 大于 threshold(maxTokens/2) 时才会进行重试,否则不予进行重试
- 每个失败的 RPC 会将 maxTokens -1
- 每个成功的 RPC 会将 token_count 增加 tokenRatio
透明重传和非透明重传
gRPC 的重试按照业务上划分可以分为三种:
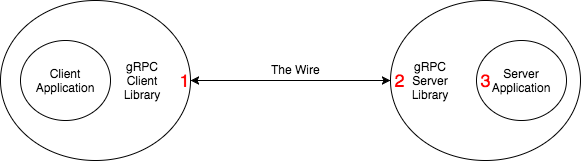
- 请求从来没有离开过客户端
- 请求到达了服务端,但是并没有触达服务端业务层
- 请求触达了服务端业务层,但是失败了
前两种被称为透明重试,这种请求对于服务端是幂等的,同时也不会造成服务端过载,因此并不会受到上述 autoRetry 策略的影响,透明重试会用户完全透明,只有非透明重试才会收到上述策略的影响。