简述 memory reordering
什么是 memory reordering
在阐述 memory reordering 之前,首先需要声明的一点是:
memory reordering 涉及到各语言编译器的具体实现以及硬件平台的设计。memory reordering 本质上其实可以简单分为三种:
- relaxed ordering:最弱的内存模型。
- acquire-release ordering:遵循 acquire and release semantics 的内存模型。
- sequential consistent ordering:连续一致性模型,没有任何 memory reordering 的可能,下文简称 SC。
三种模型从上往下,依次加强。硬件平台和各语言实现中按内存模型的强弱可以划分如下:
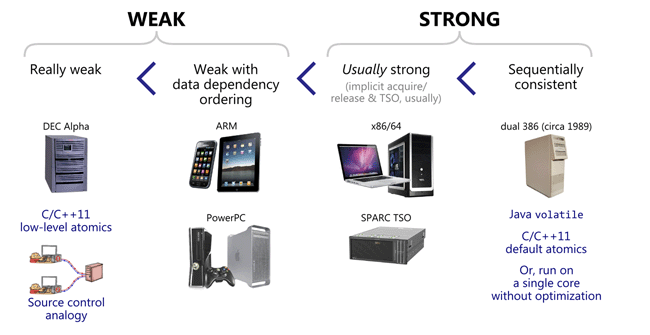
可以看到:
- DEC Alpha 是最具代表性的弱排序处理器。
- ARM 和 PowerPC 的处理器遵循了 data dependency ordering。也就是说比如我们在 C/C++ 中将 A 的值赋予 B,那么对 B 的 Load 一定是在 A 的 Load 之后的。
- x86 则是遵循 acquire-release ordering 的。
- 早期的 dual 386 没有那么先进,所以没有进行 memory reordering,所以是满足 sequential consistent ordering ,这在现代 CPU 里已经没有了。
在具体理解各种 memory reordering 之前,首先先来理解下 acquire and release semantics ,这会是一个比较好的切入点。
关于 acquire and release semantics 的定义,网上资料很多,很多看上去其实是矛盾的,jeff preshing 给出的定义是比较准确的:

- acquire semantics 即在 read-acquire 之后的内存读写操作是不允许被重排至 read-acquire 之前的。
- release semantics 即在 write-release 之前的内存读写操作是不允许被重排至 write-release 之后的。
那么通过 memory barrier 就保证了四种可能的内存乱序(LoadLoad, StoreStore, LoadStore, StoreLoad)中的三种:即 LoadLoad, StoreStore, LoadStore。如下图所示:
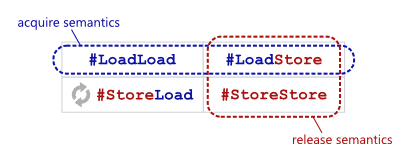
- LoadLoad 和 LoadStore 保序保证了 acquire semantics,即体现了 Load 之后的内存读写操作不允许被重排至 Load 之前。
- LoadStore 和 StoreStore 保序保证了 release semantics,即体现了 Store 之前的内存读写操作不允许被重排至 Store 之后。
- relaxed ordering 模型下,LoadLoad, StoreStore, LoadStore, StoreLoad 是可以任意互相打乱的,只要不影响单线程最终的执行结果即可。
- acquire-release ordering 保证了 LoadLoad, StoreStore, LoadStore 是保序的,只有 StoreLoad 是不保序的。
- sequential consistent ordering 则保证了 LoadLoad, StoreStore, LoadStore, StoreLoad 全都是保序的。
值得一提的一点:即使 acquire and release semantics 对 StoreLoad 不保序,但是如果 Store 和 Load 操作的是相同的内存地址,那么他们依然是保序的,因为此时如果不保序就可能会破坏单线程下的运行结果。
实际上,StoreLoad 是最难实现的。具体为何是最难实现的,后面有时间会专门拿篇文章阐述一下。
理解 C++11 里的 memory order
在编译器环节的 memory reordering ,实际上是绑定语言的。具体的,我们可以先用 C++11 中提供的六种 memory order 来阐述 memory reordering,它们分别是:
- momory_order_relaxed
- memory_order_consume
- memory_order_acquire
- memory_order_release
- memory_order_acq_rel
- memory_order_seq_cst
其中,memory_order_seq_cst 是默认的 memory order,memory_order_relaxed 和 memory_order_acquire 以及 memory_order_release 是我们比较常用的。而 memory_order_consume 和 memory_order_acq_rel 则相对较少被使用。
memory_order_relaxed
在 C++11 中 memory_order_relaxed 只保证当前操作的原子性,不保证执行的顺序性:
1 | std::atomic<int> x = 0; // global variable |
按道理来说,如果 A 总是在 B 之前执行,C 总是在 D 之前执行,那么是不可能会出现 a 和 b 同时等于 1 的情况的。但是实际运行过程中,是有可能出现的,因为编译器可能会自行调整 C 和 D 的顺序从而导致按照 D->A->B->C 这样的顺序来执行。
因此可以说明上文提到的:
memory_order_acquire,memory_order_release,memory_order_consume 和 memory_order_acq_rel
memory_order_acquire 和 memory_order_release 正是 acquire and release semantics 在 c++11 中的实现。memory_order_acquire 实现了 acquire semantics,memory_order_release 实现了 release semantics。
那么当我们将之前的程序改写成:
1 | // Thread-1: |
就可以保证 A 一定是在 B 之前执行的,C 一定是在 D 之前执行的。但是如果我们的程序是这样写的:
1 | y.store(1, memory_order_release); // D |
那么 D 和 C 的执行顺序实际上是程序本身保证不了的。
另外 memory_order_acq_rel 其实和 memory_order_acquire + memory_order_release 配对使用是没有区别的。即:
1 | // Thread-1: |
相当于 memory_order_acquire 和 memory_order_release 的结合。
而 memory_order_consume 是一种 platform specific 的对 acquire and release semantics 优化方法,这种优化依赖于处理器平台的 data dependency ordering,首先 data dependency ordering 的约束比 acquire and release semantics 来得更宽容,所以在 x86 平台上是不适用的(实际使用效果等同于 acquire and release semantics ),但是在 ARM 和 PowerPC 这种平台是可以起到优化作用的。
举个例子可能更形象一些,例子来源于 cppreference。
1 | std::atomic<std::string*> ptr; |
因为 p2 依赖 ptr,所以第一行 assert 不会失败,但是对于第二行,我们有:
the integer data is not related to the pointer to string by a data-dependency relationship, thus its value is undefined in the consumer.
当然这个事情也告诉我们,抛开其他的变量不谈,越是弱内存模型的平台越容易写出高性能的程序,同时也对程序员对底层并发掌握程度的要求也是更高的。
memory_order_seq_cst
至于 memory_order_seq_cst,这里的 seq_cst 后缀其实就是 sequential consistency ,即 SC,也就是不存在 memory reordering 的可能。
Java 中的 memory reordering
实际 Java 也在语言层面上提供了 LoadLoad,StoreStore,LoadStore 和 StoreLoad 这四种 memory barrier 。可以参照 jdk 官方的注释。下面就以 volatile 和 VarHandle 为例介绍一下它们的应用。
volatile 关键词
比如常用的 volatile 关键词具有两个特征:
- 可见性,每次读
volatile变量的时候总能读取到它最新的值,无论最后一次写入是否是当前线程完成的。 - 保证 SC 语义。
Doug Lea 给出了 JMM 中 关于 volatile 中各种行为是否允许 memory reordering 的详细说明。
| Can Reorder | 2nd operation | |||
| 1st operation | Normal Load Normal Store |
Volatile Load MonitorEnter |
Volatile Store MonitorExit |
|
| Normal Load Normal Store |
No | |||
| Volatile Load MonitorEnter |
No | No | No | |
| Volatile Store MonitorExit |
No | No | ||
在 JSR-133 中规定了这些情况里 memory barrier 的使用。
| Required barriers | 2nd operation | |||
| 1st operation | Normal Load | Normal Store | Volatile Load MonitorEnter |
Volatile Store MonitorExit |
| Normal Load | LoadStore | |||
| Normal Store | StoreStore | |||
| Volatile Load MonitorEnter |
LoadLoad | LoadStore | LoadLoad | LoadStore |
| Volatile Store MonitorExit |
StoreLoad | StoreStore | ||
JDK 9 中的 VarHandle
VarHandle 也提供了类似于 C++ 中 memory order 的用法。 VarHandle 的出现替代了 Java 里 Unsafe 的很多操作。详细地,可以参照 JEP 193。
JDK 9 之前缺乏对类中字段的底层的原子和保序的标准化接口,现有的各种 work around 的方式在官方看来都不是正道,举例来说,比如我们要原子地增加某个字段的值,可以使用三种方式:
- 使用 Java 提供的原子类,比如
AtomicInteger,增加空间开销不说, 可能会有额外的并发问题; - 使用
FieldUpdaters,反射开销太大; - 使用
sun.misc.Unsafe接口,但是 sun 开头的接口并非 oracle 官方维护,oracle 一度想在 Java 9 中将其删除或封装(参照JEP 260)。
那么在这个背景之下,VarHandle 就有很大的存在必要性。具体地,在 Java9 中提供了相应的方法用于生成对应的变量句柄。
findVarHandle:创建对象中非静态字段的VarHandle。findStaticVarHandle:创建对象中静态字段的VarHandle。unreflectVarHandle:通过反射创建VarHandle。
按照低到高提供了四种访问模式:
- plain:不确保内存可见性,opaque、release/acquire、volatile 是可以保证内存可见的。
- opaque:保证程序执行顺序,但不保证其它线程的可见顺序。
- release/acquire:保证程序执行顺序,同时实现了 acquire and release semantics,因此也同时避免了一些多线程的并发问题。
- volatile:保证程序的执行顺序,且保证变量之间不被重排序。
更加详细的效果可以参照 JFound 的测试结果,这里不再进行展开。
网上找了个 VarHandle 使用原子计数器的用法:
1 | public class Counter { |
1 | public class Counter { |
references
- https://preshing.com/20120625/memory-ordering-at-compile-time/
- https://preshing.com/20120930/weak-vs-strong-memory-models/
- http://gee.cs.oswego.edu/dl/html/j9mm.html
- http://gee.cs.oswego.edu/dl/jmm/cookbook.html
- http://dreamrunner.org/blog/2014/06/28/qian-tan-memory-reordering/
- CPU Cache and Memory Ordering ———— 何登成
- https://zhuanlan.zhihu.com/p/41872203
- https://levelup.gitconnected.com/memory-model-basic-d8b5f8fddd5f
- https://blog.csdn.net/netyeaxi/article/details/80718781
- https://stackoverflow.com/questions/19923352/whats-the-difference-of-the-usage-of-volatile-between-c-c-and-c-java
- https://stackoverflow.com/questions/65951795/implement-acquire-release-model-by-using-volatile-in-java8